Thus far I've had difficulty working out how to implement the data from the [rm.slice] external on the sample buffer [buffer samp]. I've saved it into a coll named [coll slices] that indexes the start and end points of each slice in milliseconds with floating point values for extra accuracy.

the [peek~] // [poke~] // [index~] // [record~] dilemma.
MSP has several methods to write to a buffer. Chosing which to use has been the most significant roadblock in this patch. By trialing each method and ultimately discarding [poke~], [index~] & [record~] my understanding of MSP expanded dramatically.
Unlike [poke~] and [index~], [peek~] uses values/indices to write to a buffer but is able to operate without DSP turned on (a prerequisite of my initial concept)
Use peek~ to read and write sample values to a named buffer~. Unlike related objects index~ and poke~, values and indices are specified as Max messages, and the object will function even when the audio is not turned on.I discovered a roadblock in working out how to use [peek~] to:
a) read from the primary buffer (samp)
b) write to dynamically named sequential buffers effectively.
I discovered this on the c74 forum:
> So far I am using Buffer~ and info~ to get the info on how long each
> new file should be, but i am not sure where to go next. Should I use
> peek~ or poke~ or index~…..
Just make a 2nd buffer with the length of one slice, then use uzi with
your “samples per slice” and peek~ to read the samples from the cutup
buffer into another peek~ to set the samples to the slice buffer. Then
save the slice buffer. Wrap a counter arround this somehow that
increments an offset for the first peek~ and the filename. You can also
check out bufcopy~ from Bill Orcut, also I think Eric Lyons just
released MSP Potpourri has an object for copying parts of a buffer,
forgot the name though. These might be faster than peek and uzi.
I wanted to avoid using any further externals for this project to grow more familiar with the native objects.
Whilst on the forum looking for ways to manage tasks involving numerous buffers I discovered the native [polybuffer~] object
polybuffer~ lets you operate with a group of buffer~ objects. Each buffer~ will be named after polybuffer~ first argument and an index (aka for a polybuffer~ toto object, each buffer~ will be named toto.N where N is the index).
This is my (very messy dev. version) [p peek] subpatch that takes the indices from the [coll slices] table and sends them to the first [peek~] object to read, then writes them sequentially to dynamically named buffers indexed within the polybuffer [polybuffer cuts.*]

And here is a cleaner version with annotations explaining the dataflow:
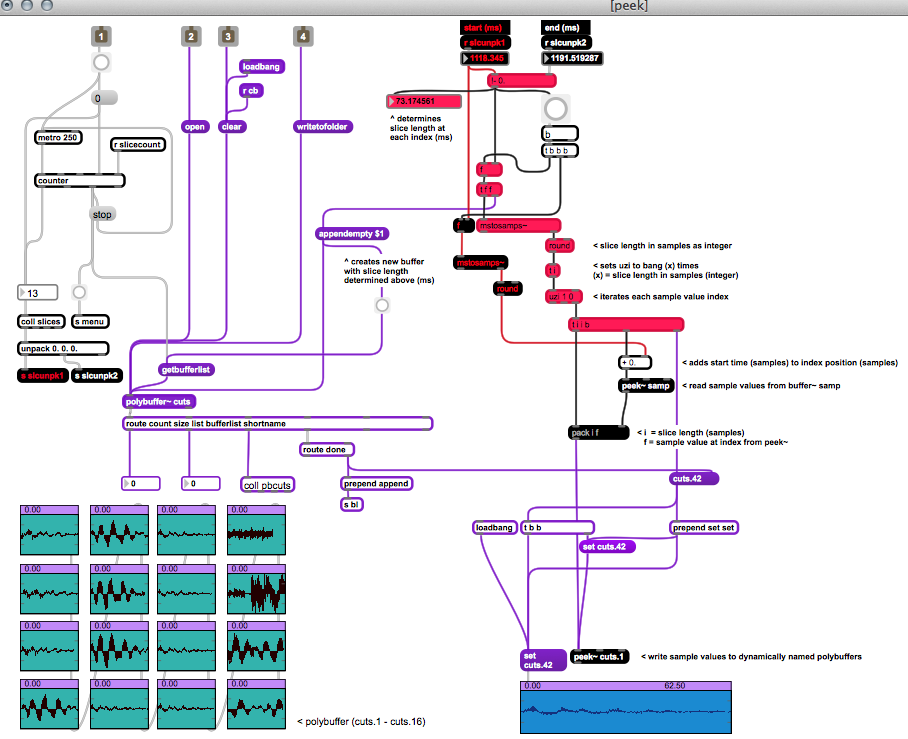
Cleaned up [p peek] subpatch with annotations
No comments:
Post a Comment